
Navigating data flows
When you open a data flow, it opens in Data flow. Data flow provides both information on the flow and its dependencies as well as an editor for designing the flow. Data flow contains two sections:
-
Overview: Provides a summary of information about the data flow, including information on dependencies, reload history, and published copies.
-
Editor: Provides the canvas for designing and editing the data flow, previewing the script, and running the flow in full.
Overview
Overview provides general information about a data flow, its data sources, and its exported files. Four tabs are available in a data flow overview:
-
Summary
-
Notifications
-
Run history
-
Published copies
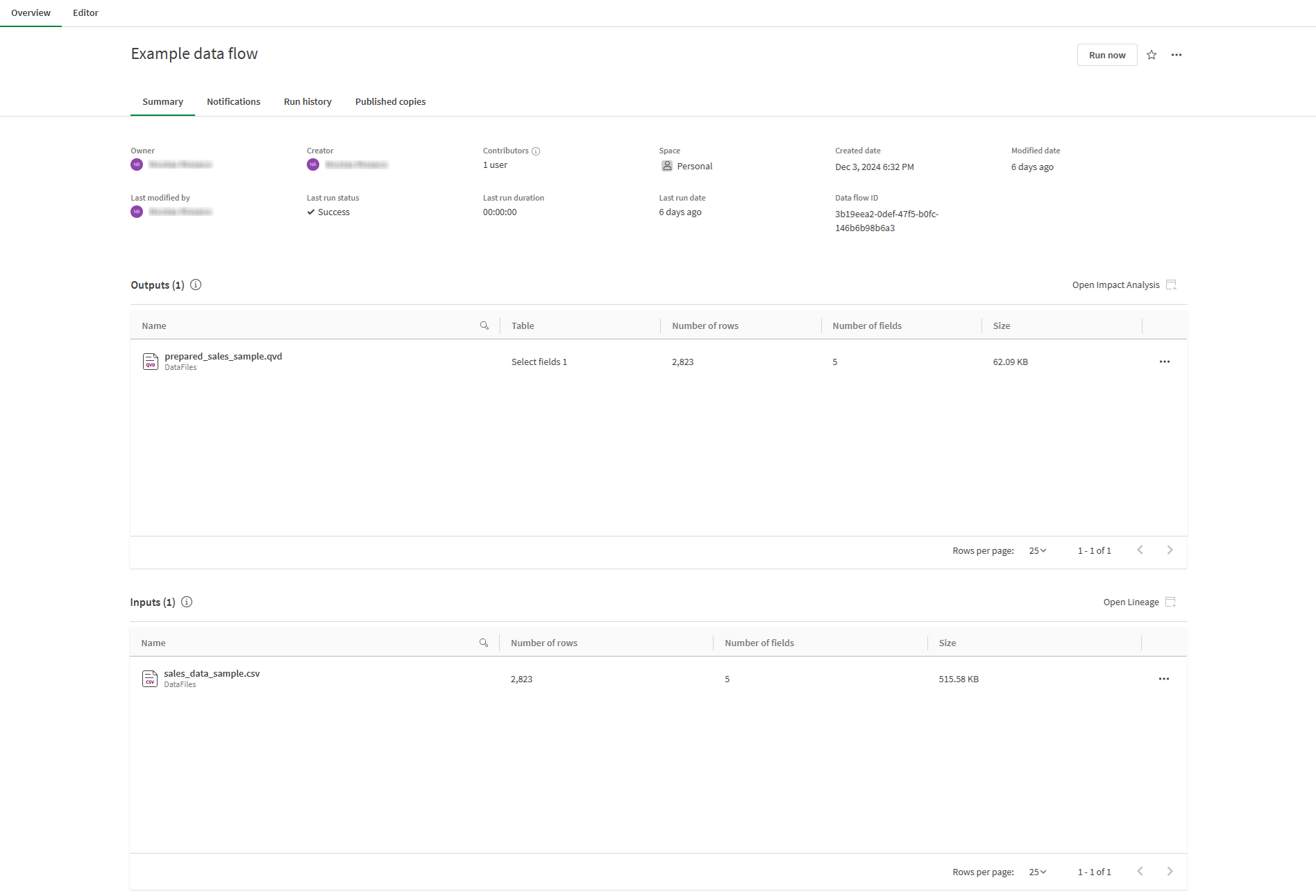
Summary
The Summary provides general information on the data flow creation, updates and status:
-
Owner: Owner of the data flow
-
Creator: Creator of the data flow
-
Contributors: Number of contributors to the data flow. Click
 to view the names of contributors.
to view the names of contributors. -
Space: Space where the data flow is located
-
Created date: Date the data flow was created
-
Modified date: Date the data flow was last modified
-
Last modified by: User who last modified the data flow
-
Last run status: Status of the last data flow run
-
Last run duration: Duration of the last data flow run
-
Last run date: Date of the last data flow run
-
Data flow ID: Technical ID of the data flow
Summary also has two additional sections, Outputs and Inputs:
-
Outputs shows the files outputted by the data flow. View the full impact analysis for your data flow by clicking Open Impact Analysis.
-
Inputs lists all sources used at the start of your data flow. View the full lineage of your data flow by clicking Open Lineage.
For items listed in Outputs and Inputs, click ![]() to view additional options. You can view the impact analysis or lineage for each item. You can also open items in a new tab.
to view additional options. You can view the impact analysis or lineage for each item. You can also open items in a new tab.
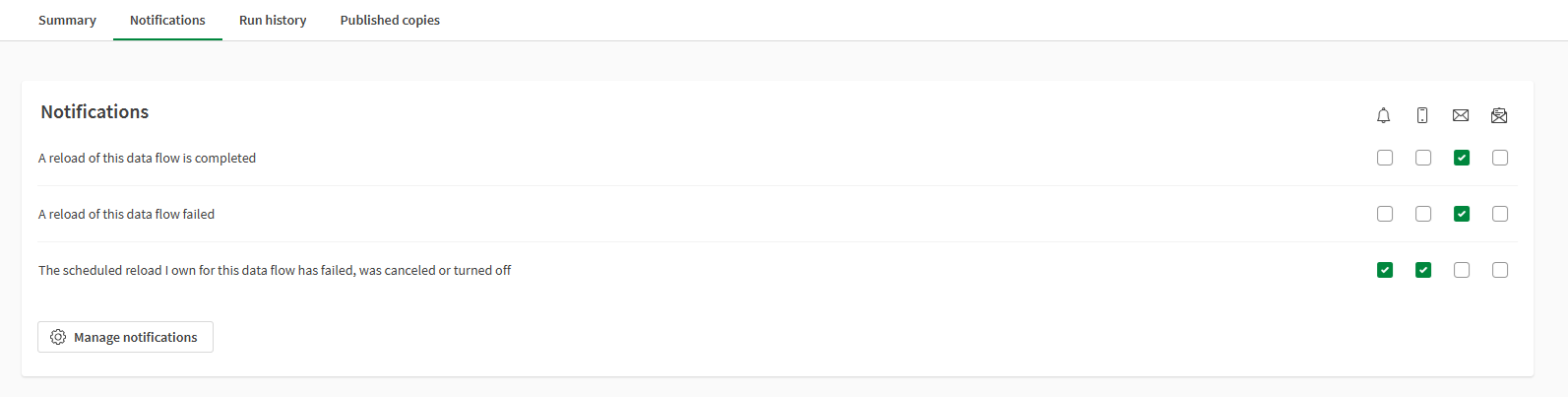
Notifications
Notifications lists the different events for which you can receive notifications. You can turn them on or off, and select how you receive the notifications.
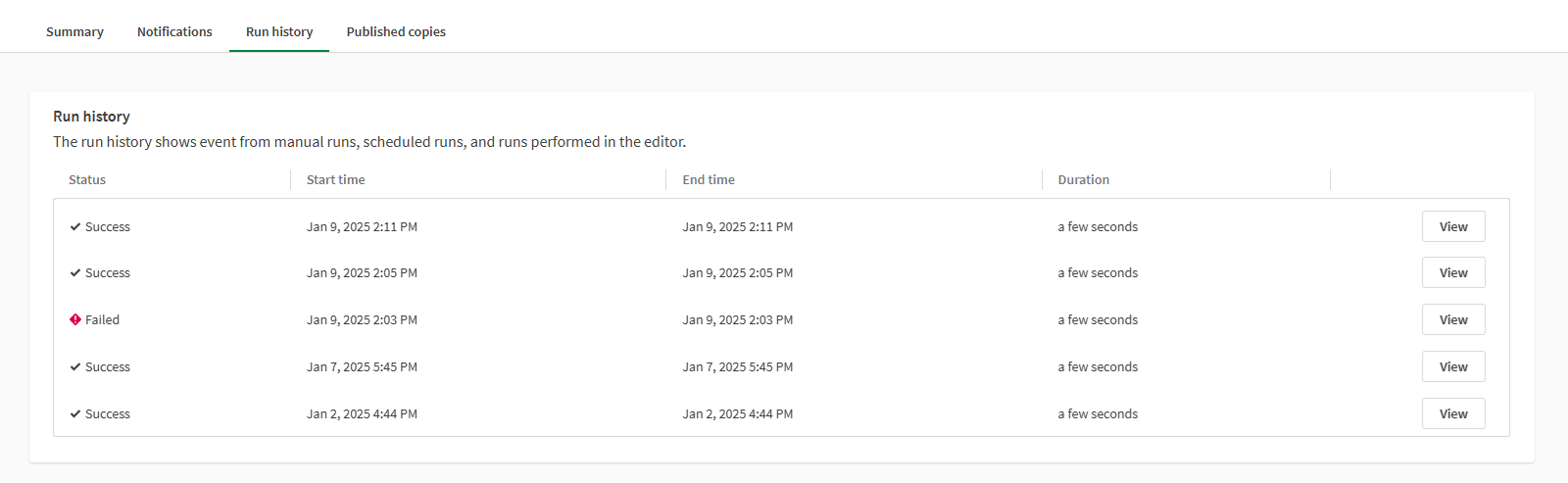
Run history
Run history shows list of the previous data flow runs, with the status, time and duration of the run. Click View to display a summary and optionally download a detailed log.
Published copies
Published copies shows in which managed spaces copies of the data flow were published. Each copy shows the following information:
-
Name
-
Owner
-
Last modified
-
Space
-
Viewed by

Click on the copy to open it in Data flow. Click ![]() to view additional options. You can:
to view additional options. You can:
-
Add it to a collection.
-
Rename it.
-
View lineage information.
-
View impact analysis.
-
View the copy run schedule.
-
Open it in a new tab.
-
Delete the copy.
Editor
In Editor, you can design and run your data flow by combining data sources, processors, and targets.
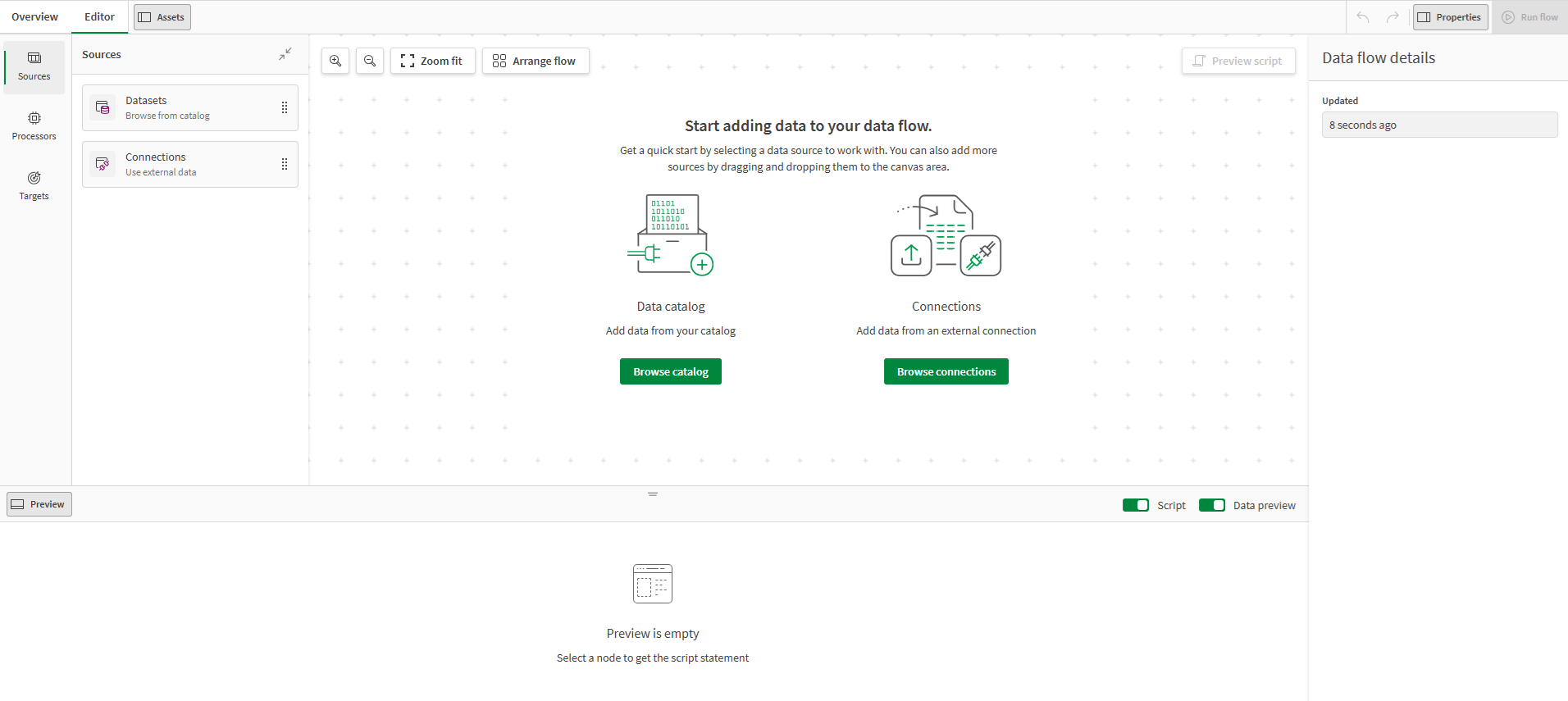
Actions and panels available in the data flow editor:
| Option | Description |
|---|---|
|
|
Show or hide the Sources, Processors and Targets panels. |
| Flow status | Current validity status of the entire data flow (requires at least one node on the canvas). This status is the result of the statuses of all the components in your data flow. |
|
|
Undo the latest change (multiple step undo is possible). |
|
|
Redo the latest undo. |
|
|
Show or hide the properties panel where you can configure nodes. |
|
|
Run the data flow to generate outputs. |
|
|
Zoom in on the canvas. |
|
|
Zoom out of the canvas. |
|
|
Center all flow components on the canvas. |
|
|
Automatically arrange and align flow components on the canvas. |
|
|
Look at the end-to-end script generated by the data flow. |
|
|
Show or hide the Preview panel where you can look at a live script and data sample preview. |
Assets
The Assets panel contains all the components that can be added to the canvas to build your data flow. These components are split into three categories:
-
Sources that contain the data you want to prepare. See Selecting a source for more information.
-
Processors that contain the preparation functions to apply on the data. See Adding processors for more information.
-
Targets to choose how to export the prepared data. See Selecting a target for more information.
When placed on the canvas, all these components will display a status to let you know what configuration is missing in order to produce a valid data flow that you can run. These statuses include:
-
Not connected: The component is missing a connection to an upstream or downstream component.
-
Not configured: Some configuration fields have not been filled in, or the configuration has not been saved yet.
-
Invalid: An error has been detected in the component configuration.
-
Deactivated: This status means that the configuration of the previous component in the flow is not complete or valid.
-
Save required: Displayed when a Calculate fields processor is stale
-
Run required: Displayed when a Qlik script processor is stale.
-
OK: The component configuration is complete and valid.
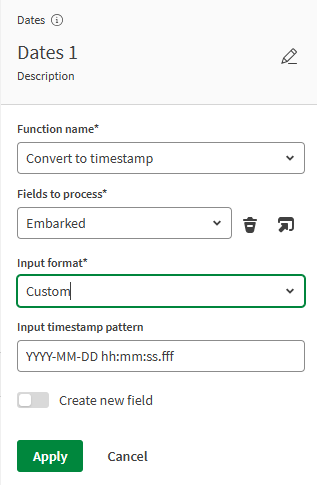
Properties
The Properties panel allows you to access the configuration of the component currently selected on the canvas. You can rename your component and add a short description.
When looking at a source, you can edit the fields loaded in the data flow. In the case of a processor, this is where you select which function to apply and where you set other configuration parameters specific to each processor. See Data flow processors for more information. Finally, when editing a target, you can select the space and path of the resulting file.
Preview
At any point during the design of your data flow, you can select a component and open the Preview panel to get a glimpse of the current state of your data, and the resulting script. To hide or show the script statement or the live data preview, use the Script and Data preview toggles in the panel header.
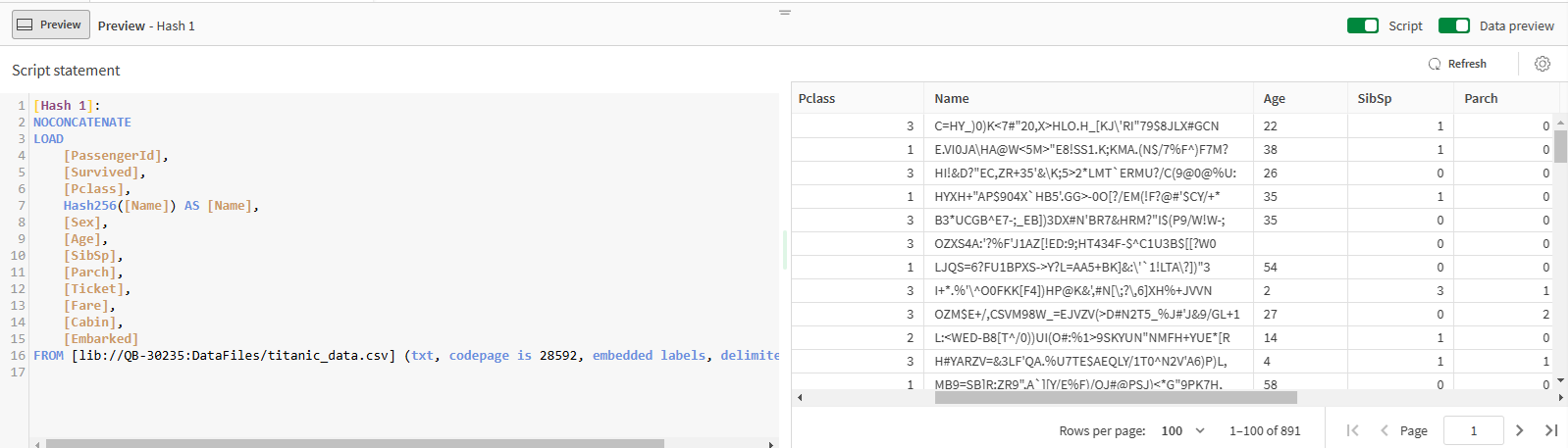
In the Data preview section of the panel, use the cog ![]() icon to set the size of the sample, and then the Refresh button to apply the change.
icon to set the size of the sample, and then the Refresh button to apply the change.