
Tutorial - Data flow for beginners
This tutorial will introduce a basic data preparation use case to make you more familiar with the different steps required in building a data flow, and the different possibilities that are offered. With the attached package containing a couple of datasets, you will be able to reproduce all the steps of this tutorial.
This scenario will focus on a sales data sample with customers from around the world, and information on their names, order dates and status, country of origin, states, addresses, phone numbers, etc. Let's say you want to prepare the data so that it focuses on the customers from the United States. You will isolate all the data on US customers, add missing information on states of origin, make a minor formatting change, and export the data to a new file that you will be able to use as source for an analytics app for example.
Prerequisites
Download this package and unzip it on your desktop:
The package contains the following data files that you need to complete the tutorial:
-
sales_data_sample.xlsx
-
states.xlsx
Adding the source files to your catalog
Before starting with the data flow creation, the two files from the package need to be available in the analytics platform. To add the source data to your catalog:
-
From the launcher menu, select Analytics > Catalog.
-
Click the Create new button on the top right and select Dataset.
-
In the window that opens, click Upload data file.
-
Drag and drop the tutorial files from your desktop onto the dedicated area of the Add file window, or click Browse to select them from their location.
-
Click Upload.
Creating the data flow and adding a source
Now that the pieces are set up, you can start creating the data flow, starting with the source.
-
From the launcher menu, select Analytics > Prepare data.
-
Click the Data flow tile or click Create new > Data flow.
-
In the Create a new data flow window, set the information of your data flow as follow and click Create:
-
Data flow tutorial as Name.
-
Personal as Space.
-
Data flow to prepare sales data focused on US customers as Description.
-
Tutorial as Tag.
Your empty data flow opens.
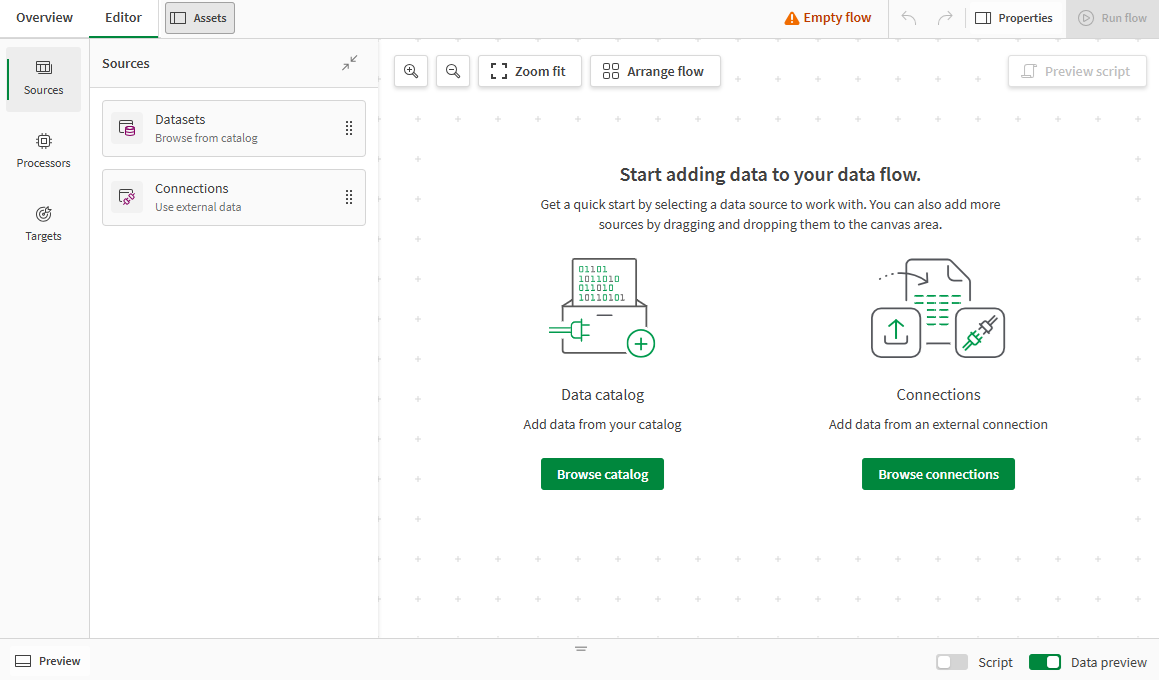
-
-
Click Browse catalog on the empty canvas to start looking at datasets that have been added to your catalog.
-
Use the filtered search to find the sales_data_sample.xlsx and states.xlsx datasets previously uploaded and select the checkboxes before their names.
-
Click Next.
-
Review the datasets and their fields in the summary, and click Load into data flow.
Both source datasets are added to the canvas, and you can start preparing the data using processors. sales_data_sample.xlsx is the main dataset you will work with, whereas states.xlsx will be used as additional data.
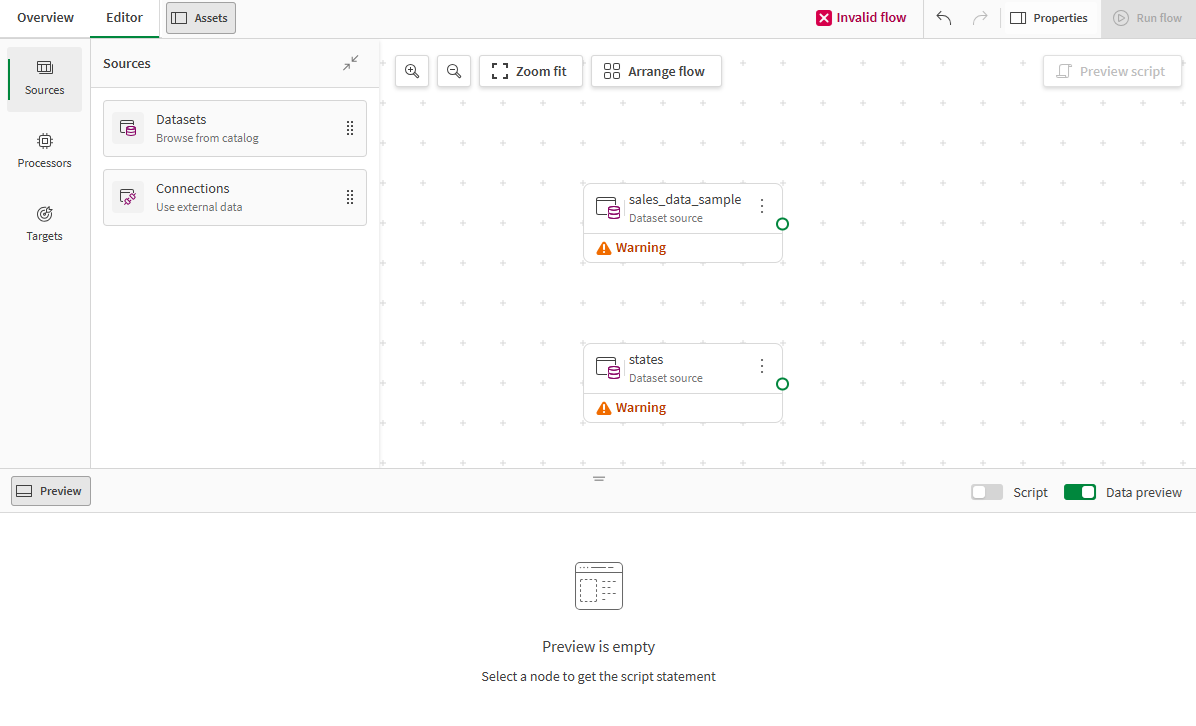
Filtering the data on US customers
You can now start preparing the data with successive changes through the use of processors. The first step is to reduce the scope of the dataset and focus on US based customers only. To do so, use the Filter processor to select only the rows that have a USA value in the COUNTRY field.
-
Click the action menu (
 ) of the sales_data_sample source on the canvas.
) of the sales_data_sample source on the canvas. -
From the menu that opens, select Add processor > Filter.

The Filter processor is placed on the canvas, already connected to the source node.
Information noteIt is also possible to manually drag and drop processors from the Processors left panel, and connect nodes manually. -
If it's not already opened, click Properties on the top right of the canvas to open the processor properties panel, where you can configure your processors and look at the data preview and script.
-
In the properties panel, click the Edit icon (
 ) next to the processor name to give the processor a more meaningful name such as US filter, and a short description like Filter on US customers for example.
) next to the processor name to give the processor a more meaningful name such as US filter, and a short description like Filter on US customers for example. -
From the Field to process drop down list, select COUNTRY.
-
From the Operator drop down list, select =.
-
In the Use with field, select Value and enter USA.
-
From the Select rows that match list, select All filters.
These parameters are more useful when combining more than one filter.
-
Click Apply.
The processor configuration is valid, but a Not connected message is still displayed because the processor does not have an output flow yet.
-
Click Preview data in the bottom panel.
Looking at the preview, you can see that only the rows with USA as country have been kept at this stage and will be propagated in the output flow. Your data flow so far should be looking as follow:

Adding state names from another dataset
In the case of the remaining US-based customers, the STATE field contains the state of origin, but as a two-letter code. You would like to make this information easier to read, with ideally the full name of the state.
The states.xlsx dataset that you have imported as source earlier happens to contain a reference of all the US states with the two-letter codes, as well as the corresponding full names. You will perform a join between those two dataset to retrieve the states names and complement your main flow.
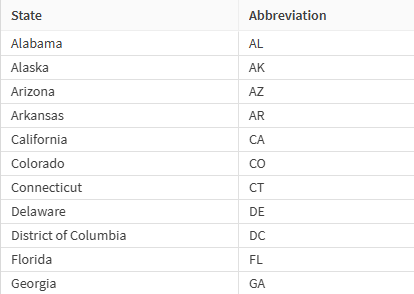
To perform the join:
-
Click the action menu (
) of the Filter processor and select Add processor to matching branch > Join. -
Rename the processor as Full state names using the Edit icon (
) in the properties panel. -
Connect the states source to the Join processor's bottom anchor point. To create a link, click the dot on the right of the source node, hold, and drag the link to the bottom dot on the left of the processor node.
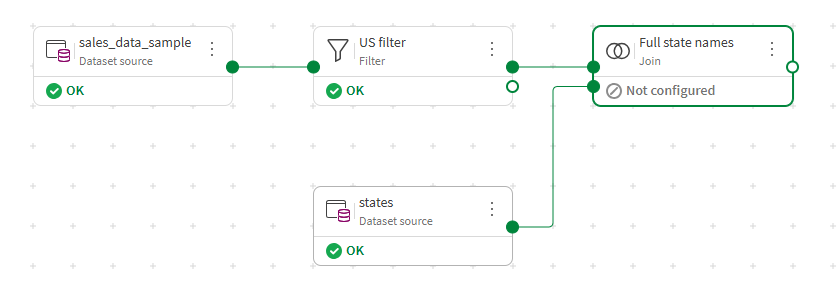
-
In the Join type drop down list, select Left outer join.
-
In the Left key drop down list, select the STATE field.
-
In the Right key drop down list, select the Abbreviation field.
The two selected columns contain the common information and allow a link between the two input flows. With a left outer join, only the additional fields from the second dataset are added to the main flow.
-
Click Apply.
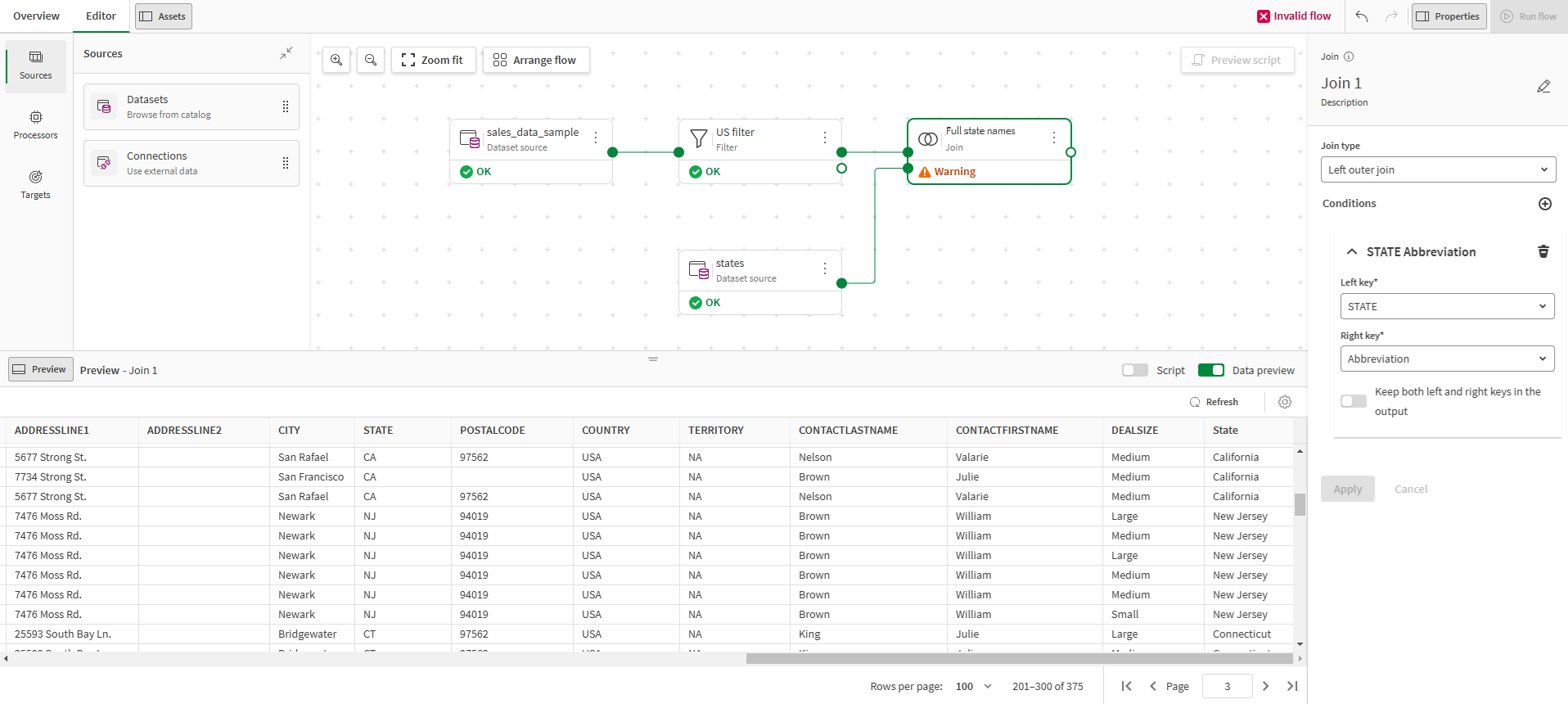
A new field State has been added at the end of the dataset, with the full state name for each customer.
Renaming and moving fields
There are now several problems with the naming and formatting of your columns. STATE and State are too similar and confusing, and the two fields are too far apart. To improve the consistency and uniformity of your fields, you can use the Select fields processor to rename and move fields around.
-
Click the action menu (
) of the Join processor and select Add processor > Select fields. -
Connect the Join processor to the Select fields processor.
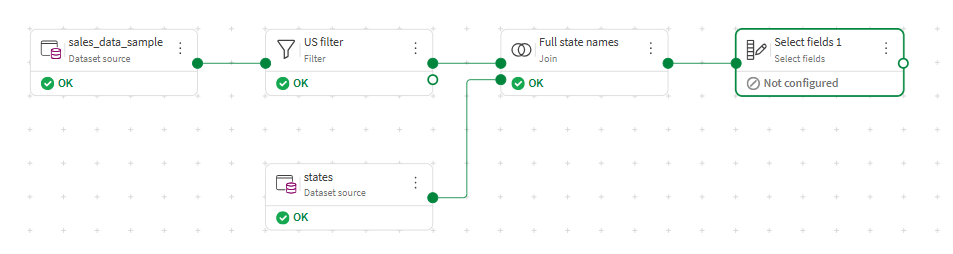
-
Rename the processor as Rename states fields using the Edit icon (
) in the properties panel. -
Point your mouse over the fields to rename and click the
Edit icon to edit the two field names as follow:-
STATE as STATECODE
-
State as STATENAME
-
-
Use the = icon to drag and drop the new STATENAME column next to STATECODE.
-
Click Apply.
You have reorganized your fields, and the data flow looks like this:
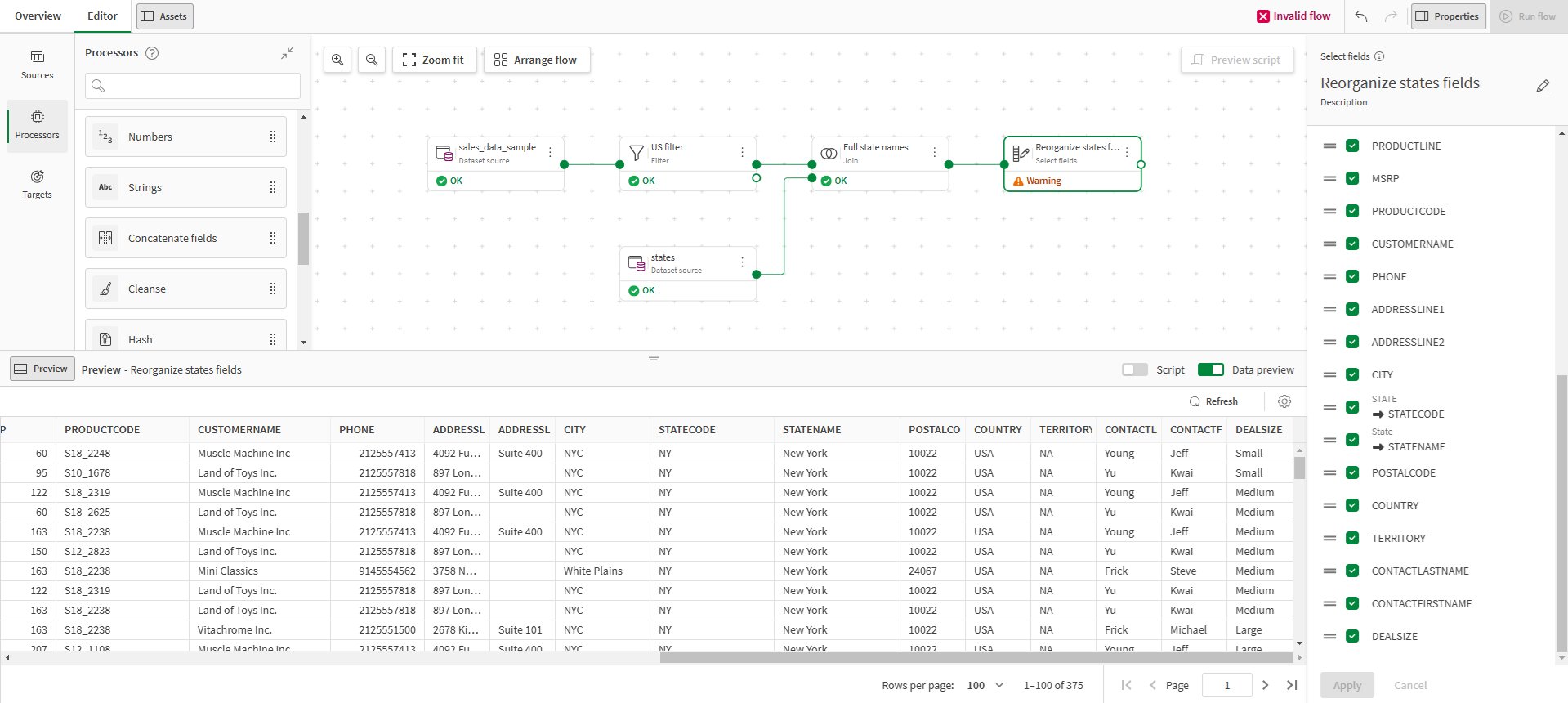
Putting customer names in upper case
In order to highlight the customers last names and make it easier to tell them apart from first names, you will use a simple formatting function of the Strings processor to put last names in upper case.
-
Click the action menu (
) of the Select fields processor and select Add processor > Strings. -
Connect the Select fields processor to the Strings processor.

-
Rename the processor as Upper case using the Edit icon (
) in the properties panel. -
In the Function name drop down list, select Change to upper case.
-
In the Fields to process drop down list, select CONTACTLASTNAME.
-
Click Apply.
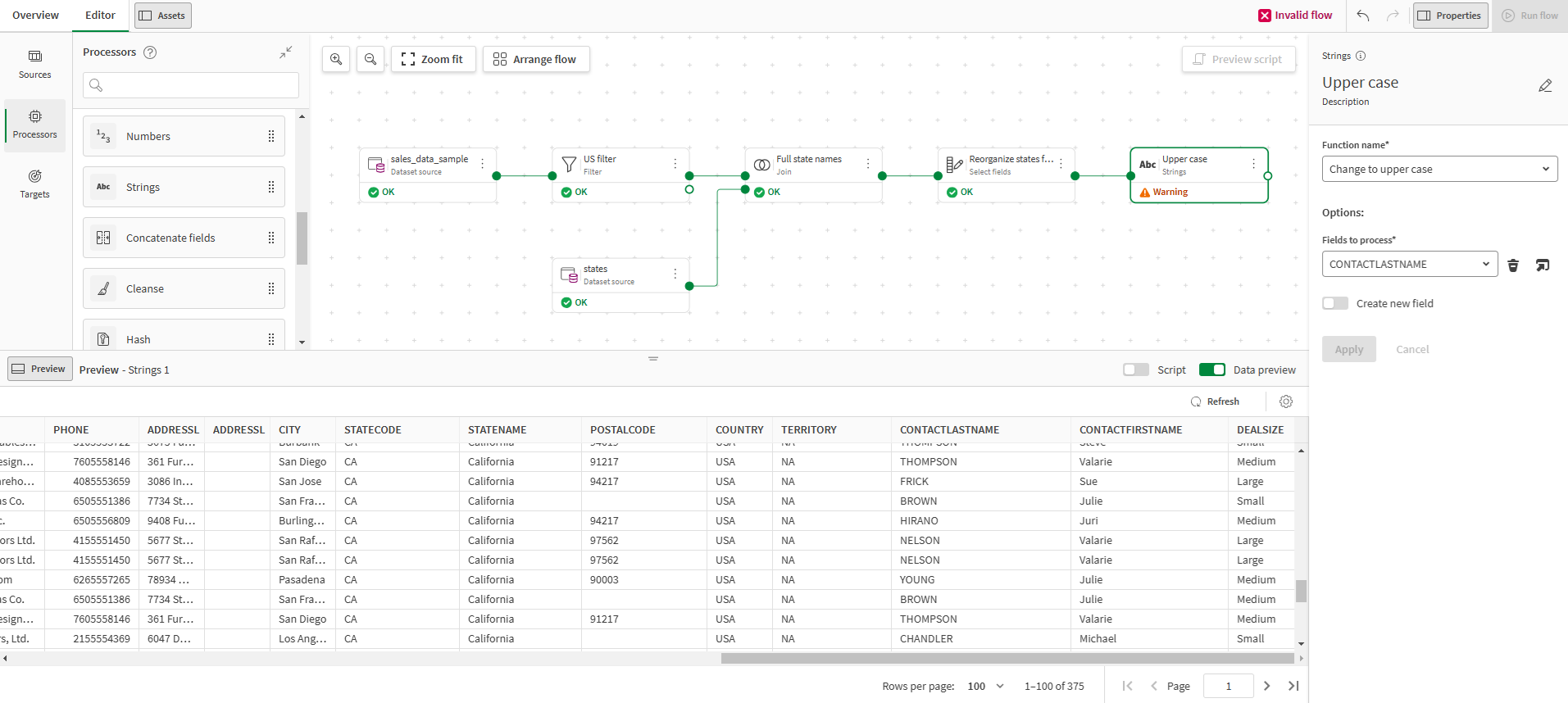
Adding a target and running the data flow
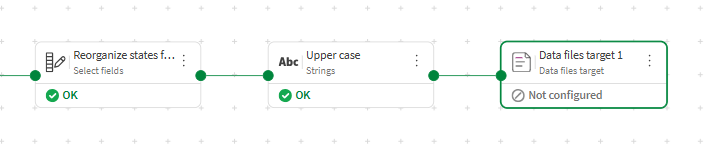
The main preparation steps are done, and you can now finalize the data flow by configuring how to export the resulting data. In this scenario, you will export the prepared data as a .qvd file stored directly in your catalog, making it convenient to use in an analytics app later for example.
-
Click the action menu (
) of the Strings processor and select Add target > Data files. -
Connect the Strings processor to the Data files target.
-
Rename the processor as QVD target using the Edit icon (
) in the properties panel. -
In the Space drop down list, select Personal.
-
In the File name field, enter tutorial_output.
-
In the Extension drop down list, select .qvd.
-
Click Apply.
Your data flow is now complete and valid as shown by the status in the header bar, and the green ticks under each source, processor and target node.
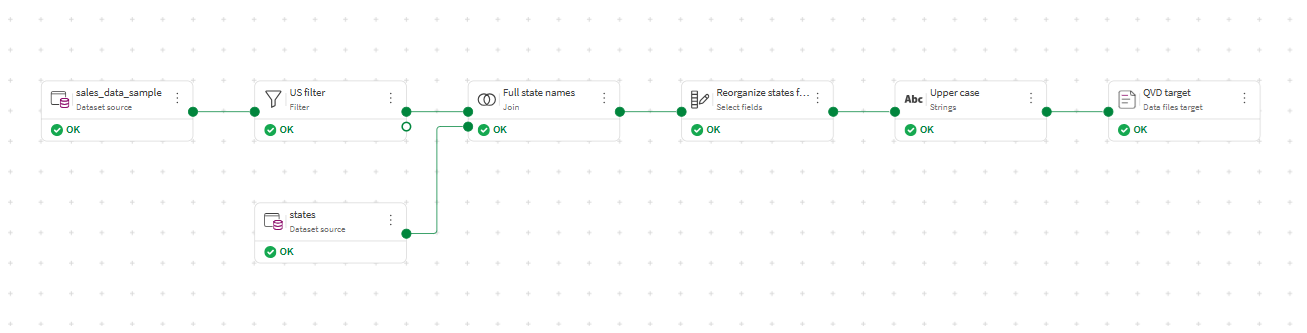
-
Click the Run flow button on the top right of the window.
A modal opens to show the progress of the run.
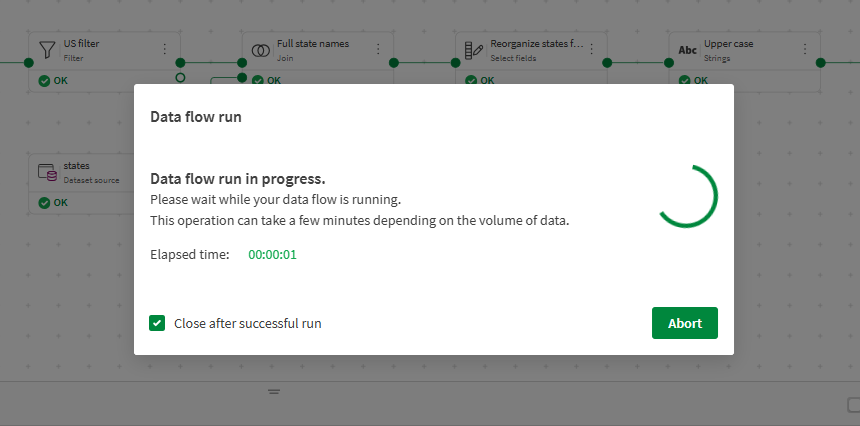
After some time, the window closes and a notification opens to tell you if the run was successful or not. The output of the data flow can now be found in your catalog, or in the Outputs section of the data flow Overview panel.
What's next
You have learned how to import source data into your catalog, build a simple data flow to filter and improve your data, and export the result of you preparation as a ready to use file.
To learn about the multiple ways to use data flow for your own use cases, you can take a look at the full list of Data flow processors and the functions they offer.
To learn how to use your prepared data in analytics applications, see Creating analytics and visualizing data.