
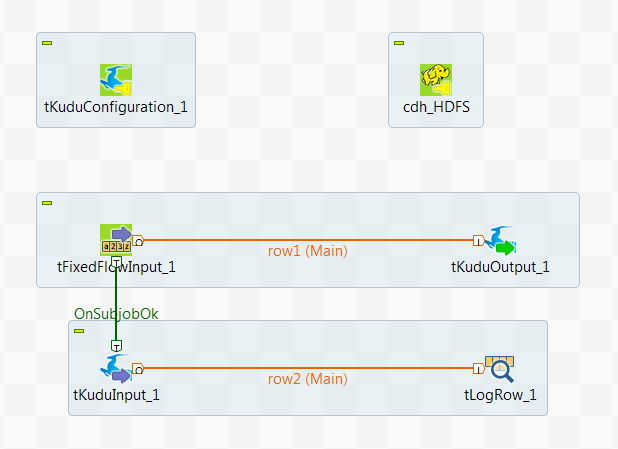
Writing and reading data from Cloudera Kudu using a Spark Batch Job
In this scenario, you create a Spark Batch Job using the Kudu components to partition and write data in a Kudu table and then read some of the data from Kudu.
This scenario applies only to subscription-based Talend products with Big Data.
01;ychen;30
02;john;40
03;yoko;20
04;tom;60
05;martin;50This data contains the names of some persons, the ID numbers distributed to these persons and their ages.
The ages are made distinct one from another on purpose because this column is the primary key column and is used for range partitioning in this scenario.
Note that the sample data is created for demonstration purposes only.
-
Ensure that the Spark cluster and the Cloudera Kudu database to be used have been properly installed and are running.
-
Ensure that the client machine on which the Talend Jobs are executed can recognize the host names of the nodes of the Hadoop cluster to be used. For this purpose, add the IP address/hostname mapping entries for the services of that Hadoop cluster in the hosts file of the client machine.
For example, if the host name of the Hadoop Namenode server is talend-cdh550.weave.local and its IP address is 192.168.x.x, the mapping entry reads 192.168.x.x talend-cdh550.weave.local.
-
If the cluster to be used is secured with Kerberos, ensure that you have properly installed and configured Kerberos on the machine on which your Talend Job is executed. Depending on the Kerberos mode being used, the Kerberos kinit ticket or keytab must be available on that machine.
For further information, search for how to use Kerberos in Talend Studio with Big Data on Talend Help Center.
-
Define the Hadoop connection metadata from the Hadoop cluster node in Repository. This way, you can not only reuse this connection in different Jobs but also ensure that the connection to your Hadoop cluster has been properly set up and is working well when you use this connection in your Jobs.
For further information about setting up a reusable Hadoop connection, see Centralizing Hadoop connection metadata