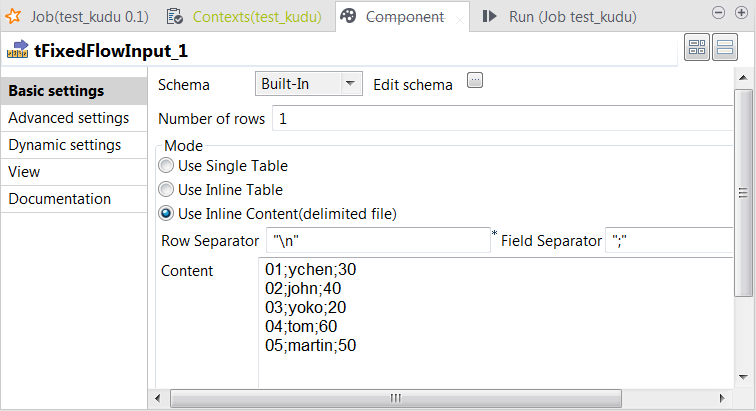
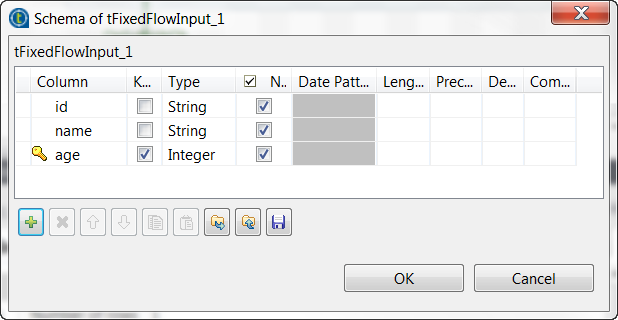
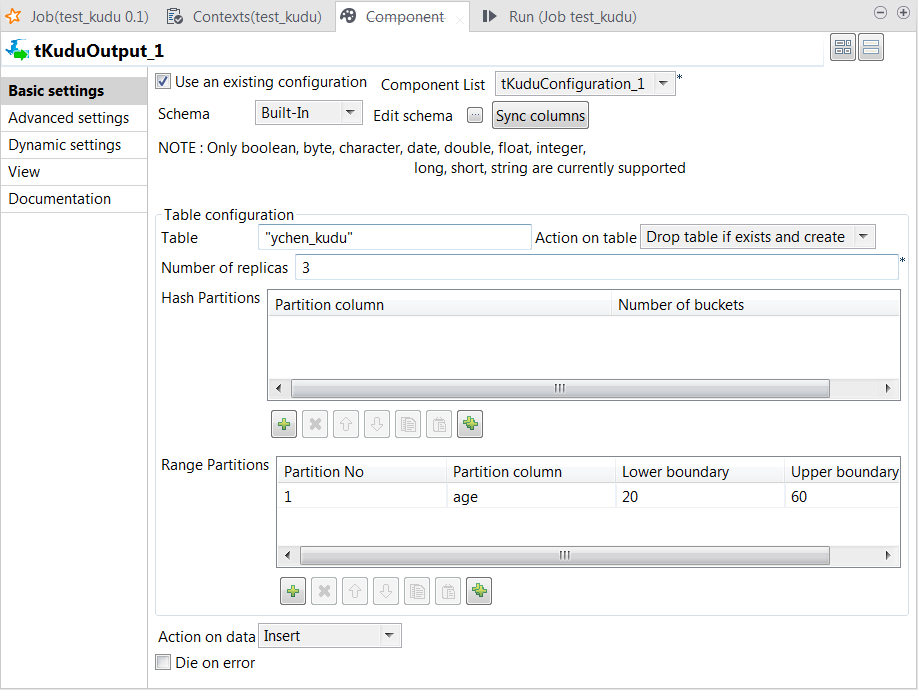
This partitioning definition creates the partition schema reading as
follows:
RANGE (age) (
PARTITION 20 <= VALUES < 60
)
According
to this partition schema, the record falling on the lower boundary, the age
20, is included in this partition and thus is written in
Kudu but the record falling on the upper boundary, the age
60, is excluded and is not written in Kudu.
In the
real-world practice, if you need to write all the data in the Kudu table, define
more partitions to receive the data with proper boundaries.