
Finalizing and executing the analysis of a set of columns
What is left before executing this set of columns analysis is to define the indicator settings, data filter and analysis parameters.
Before you begin
Procedure
-
In the Analysis Parameters view:
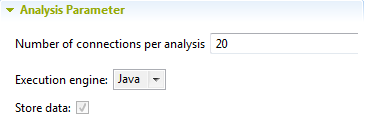
- In the Number of connections per analysis
field, set the number of concurrent connections allowed per analysis to the
selected database connection.
You can set this number according to the database available resources, that is the number of concurrent connections each database can support.
- From the Execution engine list, select the engine,
Java, or SQL, you want to use to execute the analysis.
- If you select the Java engine, the Store data
check box is selected by default and cannot be unselected. Once the
analysis is executed, the profiling results are always available
locally to drill down through the view.
Executing the analysis with the Java engine uses disk space as all data is retrieved and stored locally. If you want to free up some space, you may delete the data stored in the main Talend Studio directory, at Talend-Studio/workspace/project_name/Work_MapDB.
- If you select the SQL engine, you can use the Store
data check box to decide whether to store locally
the analyzed data and access it in the view.Information noteNote: If the data you are analyzing is very big, it is advisable to leave the Store data check box unselected in order not to store the results at the end of the analysis computation.
- If you select the Java engine, the Store data
check box is selected by default and cannot be unselected. Once the
analysis is executed, the profiling results are always available
locally to drill down through the view.
- In the Number of connections per analysis
field, set the number of concurrent connections allowed per analysis to the
selected database connection.
-
Save the analysis and press F6 to
execute it.
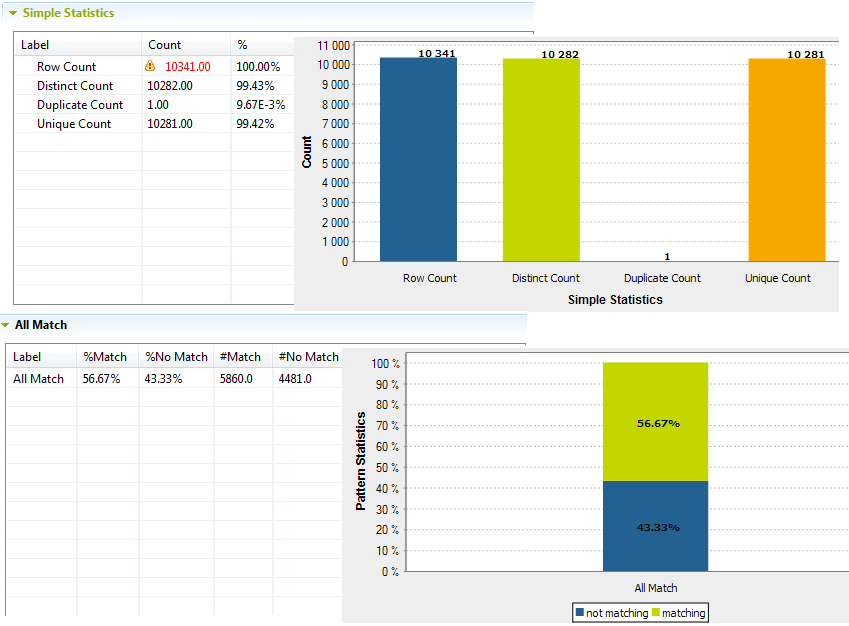
The analysis editor switches to the Analysis Results view where you can read the analysis results in tables and graphics. The graphical result provides the simple statistics on the full records of the analyzed column set and not on the values within each column separately.
When you use patterns to match the content of the set of columns, another graphic is displayed to illustrate the match and non-match results against the totality of the used patterns.