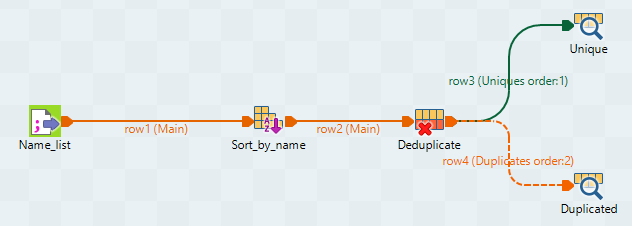
In this five-component Job, we will sort entries on an input name list, find out duplicated names, and display the unique names and the duplicated names on the Run tab.
If you find any issues with this page or its content – a typo, a missing step, or a technical error – please let us know!