
Talend Cloud Pipeline Designer concepts
This diagram and these definitions will help you understand the main concepts of Talend Cloud Pipeline Designer.
-
Remote Engine Gen2
: A Remote Engine Gen2 is a
secure execution engine on which you can safely run pipelines. It allows you to have
control over your execution environment and resources as you are able to create and
configure the engine in your own environment (Virtual Private Cloud or on premises).
A Remote Engine Gen2 ensures:
-
Data processing in a safe and secure environment as Talend never has access to the data and resources of your pipelines
-
Optimal performance and security by increasing the data locality instead of moving large data to computation
-
- Cloud Engine for Design : The Cloud Engine is a built-in runner that allows users to easily design pipelines without having to set up any processing engines. With this engine you can run two pipelines in parallel. For advanced processing of data it is recommended to install the secure Remote Engine Gen2.
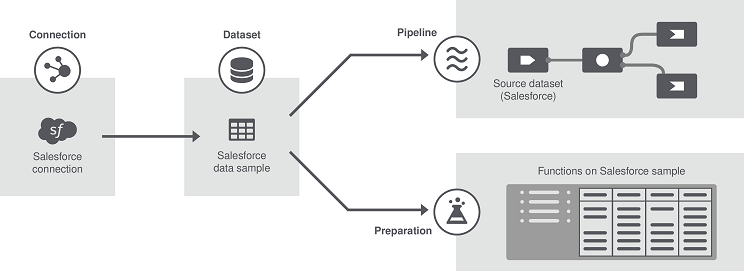
- Connection: Connections are environments or systems where datasets are stored, including databases, file systems, distributed systems or platforms, etc. The connection information to these systems only needs to be set up once since they are reusable.
- Dataset: Datasets are collections of data. They can be database tables, file names, topics (Kafka), file paths (HDFS), etc. You also have the possibility to create test datasets that you enter manually and store in a test connection, and even import local files as datasets. Several datasets can be connected to the same system (One-to-many connectivity) and are stored in reusable connections.
-
Pipeline: Pipelines consist of a process (similar to a Talend Job)
that keeps on listening to incoming data, and a pipe where data comes from a source, the
dataset, and is sent to a destination. Pipelines can be:
-
Batch, or bounded, which means the data is collected and the pipeline stops once all data is processed
-
Streaming, or unbounded, which means the pipeline never stops reading data unless you stop it
-
- Processor: Processors are components that you can add to your pipelines in order to transform your incoming batch or streaming data and return the transformed data to the next step of the pipeline.
- Sample: Your data will be visible in the form of a sample, retrieved from the dataset metadata.