
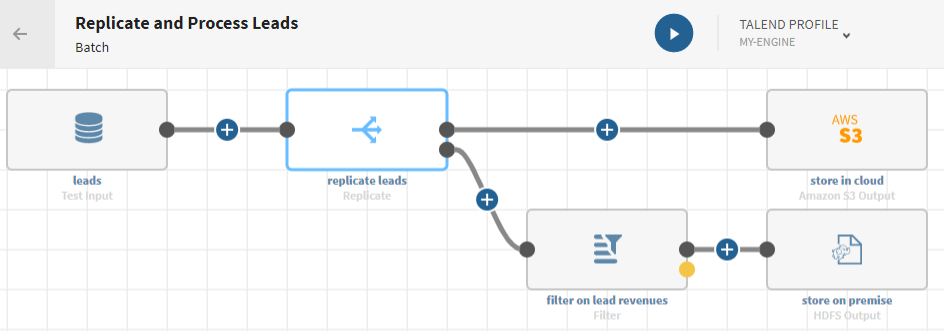
Replicating a list of leads and processing the two output flows differently
Before you begin
-
You have previously created a connection to the system storing your source data.
Here, a database connection.
-
You have previously added the dataset holding your source data.
Download and extract the file: filter-python-customers.zip. It contains lead data including ID, name, revenue, etc.
-
You also have created the connection and the related dataset that will hold the processed data.
Here, a file stored on Amazon S3 and a file stored on HDFS.
Procedure
-
Click
 and add a Replicate processor to the pipeline. The
flow is duplicated and the configuration panel opens.
and add a Replicate processor to the pipeline. The
flow is duplicated and the configuration panel opens.
-
Click next to the bottom ADD DESTINATION item on the
pipeline and add a Filter processor.
-
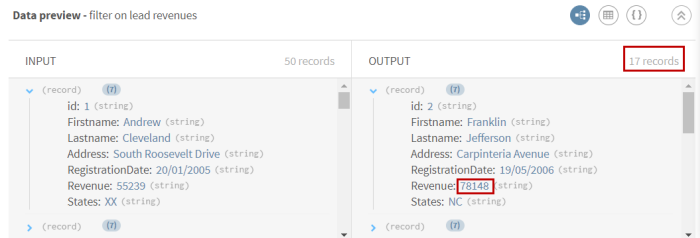
(Optional) Look at the Filter processor preview to see your data after the filtering operation.
Example
Results
Your pipeline is being executed, the records are duplicated and filtered, and the output flows are sent to the target systems you have indicated.