Use Case: Creating a pipeline to process financial data
How to create a pipeline that will enrich and filter hierarchical financial data (IBAN, account and transaction information, etc.), then aggregate and count the total amount of performed transactions.

Procedure
-
On the top toolbar, click the
 pencil icon next to the pipeline default name and give a meaningful name to
your pipeline.
pencil icon next to the pipeline default name and give a meaningful name to
your pipeline.
Example
Process financial data -
Click
 and add a Python 3 processor to the pipeline. This
processor will be used to copy Python code that will process and enrich input
data.
and add a Python 3 processor to the pipeline. This
processor will be used to copy Python code that will process and enrich input
data.
-
Click Save to save your configuration.
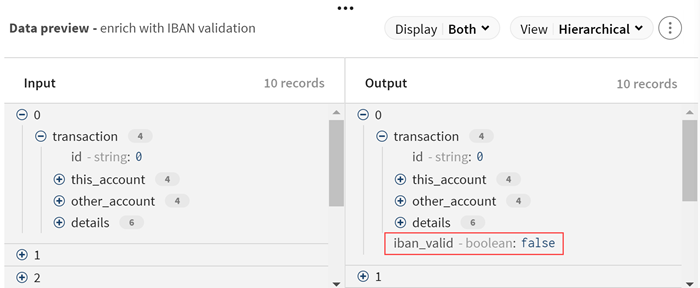
Input data is processed accordingly and you can preview the modifications. The new iban_valid field is added to all records.
-
Click and add a Filter processor to the pipeline. This
processor will be used to isolate accepted transactions (tagged with
AC, compared to DC, declined
transactions).
-
In the Filters area:
Input data is processed accordingly and you can preview the modifications. Only records containing accepted transactions (AC) are kept in the output.

-
Click and add an Aggregate processor to the pipeline. This
processor will be used to group transactions and calculate the total amount of these
transactions.
-
In the Operations
area, add an aggregate operation:
- Select .transaction.details.value.amount in the Field path list and Sum in the Operation list.
- Name the generated field, total_amount for example.
- Click Save to save your configuration.
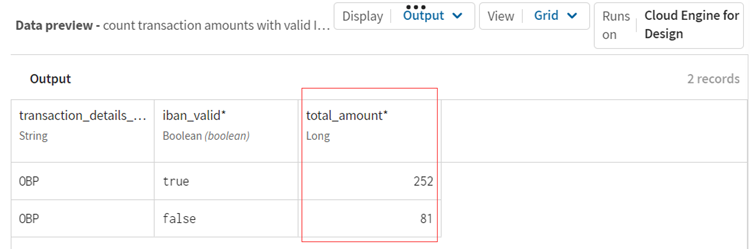
Input data is processed accordingly and you can preview the calculated data after the filtering and grouping operation. There are 252 transactions with a valid IBAN and 81 transactions with a non-valid IBAN.