Deduplicating values in columns
You can use the Deduplicate rows with identical values function to easily delete rows that are partly or entirely duplicates with other ones.
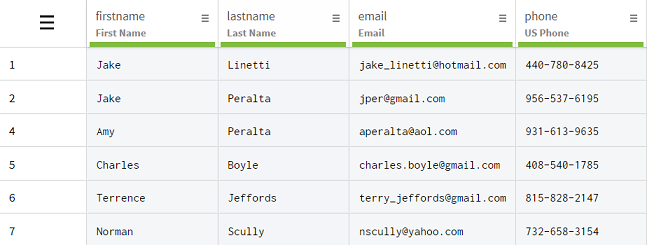
Duplicated information can be introduced in spreadsheets because of human error, like a bad copy and paste for example, as well as automated operations. In the following dataset, that contains basic customers information, you will notice that the firstname and lastname columns both contain values that are present more than once.
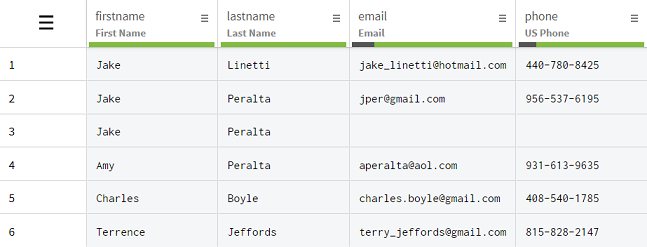
Jake and Peralta are indeed entries that make it look like the firstname and lastname columns contain duplicates when taken separately. But looking more closely shows that the information from rows 1, 2 and 4 belong to separate customers that share either their first or last names. Row 3 on the other hand is a legitimate duplicate of row 2, and is even missing some information.
Because performing a deduplication operation on the two columns separately would make you lose valuable information on customers that happen to have the same first name or last name, you will use the Deduplicate rows with identical values function on the two columns at once. This way, the function will only remove rows were both first and last names are duplicates, like rows 2 and 3, but also other potential duplicates further down in the dataset.
Procedure
Results