Bulk-writing the actors data in Neo4j
Procedure
-
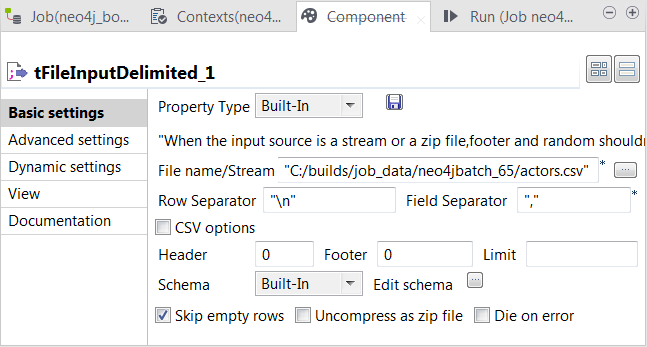
Double-click the first tFileInputDelimited component to open its Component view.
-
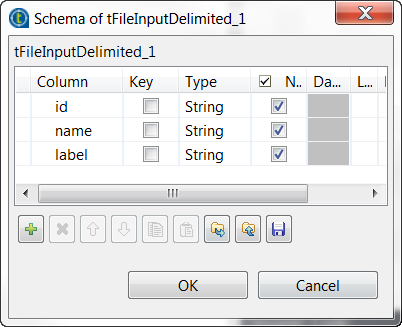
Click the [...] button next to Edit schema to open the schema editor, and define the input schema based on
the structure of the input file.
In this example, the columns are id, name and label, all of type String.
-
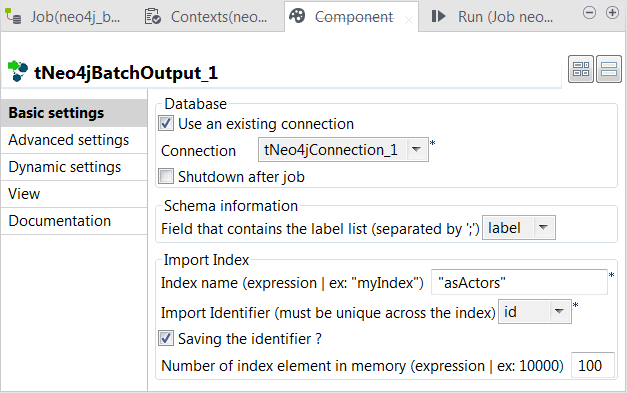
Double-click the first tNeo4jBatchOutput component to open its
Component view.