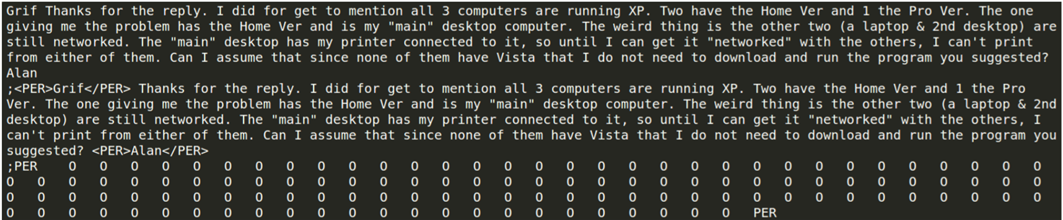
Natural Language Processing using Talend Studio
What is natural language processing?
-
text tokenization, which divides a text into basic units such as words or punctuation marks;
-
sentence splitting, which divides the input into sentences, based on ending characters, such as periods or question marks; and
-
named entity recognition, which finds and classify person names, dates, locations and organizations in a text.
-
extract person names or company names from textual resources;
-
group forum discussions together by topics;
-
find discussions where people are mentioned but don't participate to the discussion; or
-
link entities.
Workflow
-
the first one with the tNLPPreprocessing and the tNormalize components; and
-
the second one with the tNLPModel component.
While the second phase is implemented by a third Job with the tNLPPredict component.
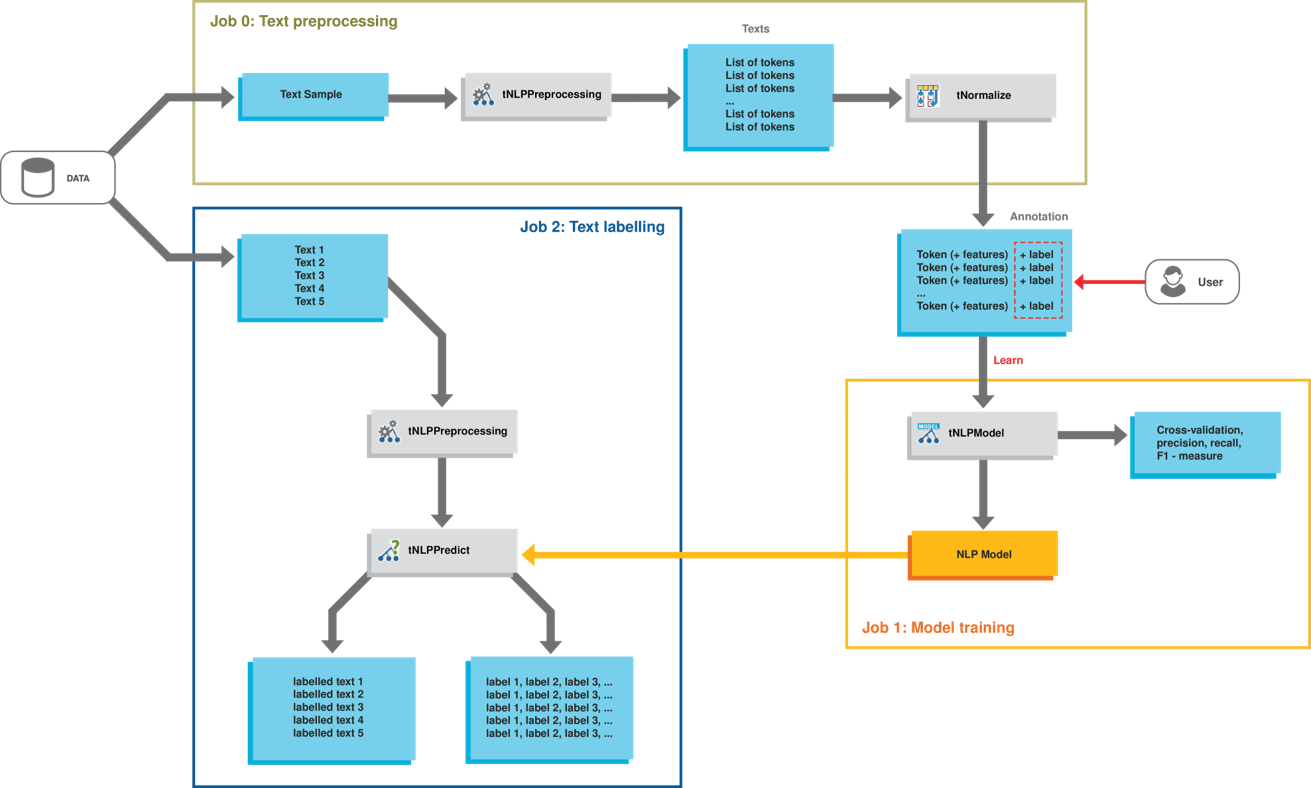
-
divides a text sample in tokens; and
-
cleans the text sample by removing all HTML tags.
Then, tNormalize converts tokens to the CoNLL format.
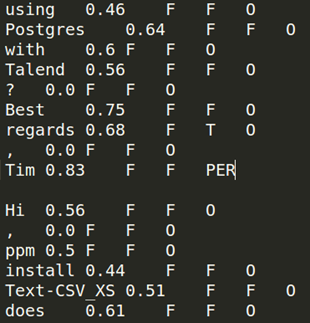
-
generates fatures for each token; and
-
trains a classification model.
tNLPPredict labels text data automatically using the classification model generated by tNLPModel.