
Downplaying the weight of the irrelevant words in each message
Procedure
-
Double-click the tModelEncoder component labelled tf_idf to open its Component view. In this process, tModelEncoder reduces the weight of the words that appears very
often but in too many messages, because a word like this often brings no
meaningful information for text analysis, such as the word the.

-
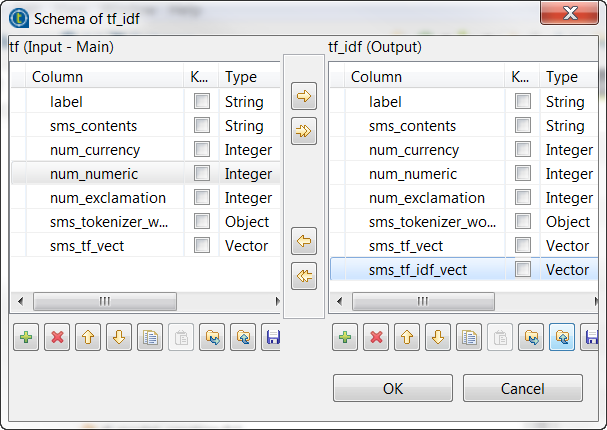
Repeat the operations described previously over the tModelEncoder labelled Tokenizer to add the sms_tf_idf_vect column of the Vector type to the output schema and define the
transformation as displayed in the image above.
 In this transformation, tModelEncoder uses Inverse Document Frequency to downplay the weight of the words that appears in 5 or more than 5 messages.
In this transformation, tModelEncoder uses Inverse Document Frequency to downplay the weight of the words that appears in 5 or more than 5 messages.