Reading and writing Avro data from Kafka using Standard Jobs
This scenario explains how to use schema registry with deserializer and how to handle
Avro data using ConsumerRecord and ProducerRecord from Kafka components in your Standard
Jobs.
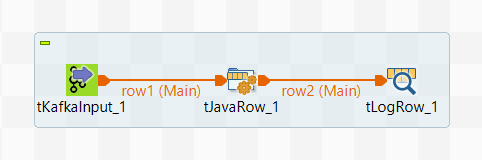
In this scenario, you first create a Standard Job to read Avro data using ConsumerRecord
that will be called the reading Job:
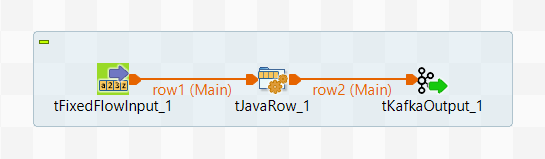
And then you create another Standard Job to write Avro data using ProducerRecord that
will be called the writing Job:
This scenario applies only to Talend products
with Big Data and Talend Data Fabric.