
Writing and reading data from Azure Data Lake Storage using Spark (Azure Databricks)
In this scenario, you create a Spark Batch Job using tAzureFSConfiguration and the Parquet components to write data on Azure Data Lake Storage and then read the data from Azure.
This scenario applies only to subscription-based Talend products with Big Data.
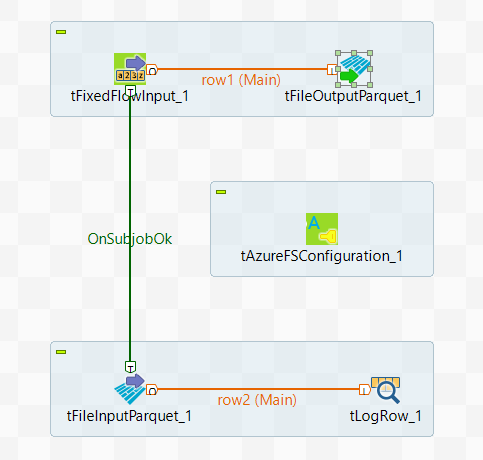
The sample data reads as
follows:
01;ychenThis data contains a user name and the ID number distributed to this user.
Note that the sample data is created for demonstration purposes only.