
tRuleSurvivorship properties for Apache Spark Batch
These properties are used to configure tRuleSurvivorship running in the Spark Batch Job framework.
The Spark Batch tRuleSurvivorship component belongs to the Data Quality family.
The component in this framework is available in all Talend Platform products with Big Data and in Talend Data Fabric.
Basic settings
|
Schema and Edit schema |
A schema is a row description. It defines the number of fields (columns) to be processed and passed on to the next component. When you create a Spark Job, avoid the reserved word line when naming the fields. This component provides two read-only columns:
When a survivor record is created, the CONFLICT column does not show the conflicting columns if the conflicts have been resolved by the conflict rules. |
|
|
Built-In: You create and store the schema locally for this component only. |
|
|
Repository: You have already created the schema and stored it in the Repository. You can reuse it in various projects and Job designs. |
|
Group identifier |
Select the column whose content indicates the required group identifiers from the input schema. |
|
Rule package name |
Type in the name of the rule package you want to create with this component. |
| Generate rules and survivorship flow |
Once you have defined all of the rules of a rule package or modified some of them
with this component, click the Information noteNote:
This step is necessary to validate these changes and take them into account at runtime. If the rule package of the same name exists already in the Repository, these changes will overwrite it once validated, otherwise the Repository one takes the priority during execution. Information noteWarning: In a rule package, two rules cannot use the same
name.
|
|
Rule table |
Complete this table to create a complete survivor validation flow. Basically, each given rule is defined as an execution step, so in the top-down order within this table, these rules form a sequence and thus a flow takes shape. The columns of this table are:
Order: From the list, select the execution order of the
rules you are creating so as to define a survivor validation flow. The types of order may be:
Rule Name: Type in the name of each rule you are creating. This column is only available to the Sequential rules as they define the steps of the survivor validation flow. Do not use special characters in rule names, otherwise the Job may not run correctly. Rule names are case insensitive. Reference column: Select the column you need to apply a given rule on. They are the columns you have defined in the schema of this component. This column is not available to the Multi-target rules as they define only the Target column.
Function: Select the type of validation operation to be
performed on a given Reference column. The available types include:
Value: enter the expression of interest corresponding to the Match regex or the Expression function you have selected in the Function column. Target column: when a step is executed, it validates a record field value from a given Reference column and selects the corresponding value as the best from a given Target column. Select this Target column from the schema columns of this component. Ignore blanks: Select the check boxes which correspond to the names of the columns for which you want the blank value to be ignored. |
|
Define conflict rule |
Select this check box to be able to create rules to resolve conflicts in the Conflict rule table. |
|
Conflict rule table |
Complete this table to create rules to resolve conflicts. The columns of this table are: Rule name: Type in the name of each rule you are creating. Do not use special characters in rule names, otherwise the Job may not run correctly. Conflicting column:When a step is executed, it validates a record field value from a given Reference column and selects the corresponding value as the best from a given Conflicting column. Select this Conflicting column from the schema columns of this component.
Function: Select the type of
validation operation to be performed on a given Conflicting
column. The available types include those in the Rule
table and the following ones:
Value: enter the expression of interest corresponding to the Match regex or the Expression function you have selected in the Function column. Reference column: Select the column you need to apply a given conflicting rule on. They are the columns you have defined in the schema of this component. Ignore blanks: Select the check boxes which correspond to the names of the columns for which you want the blank value to be ignored. Disable: Select the check box to disable the corresponding rule. |
Advanced settings
|
Set the number of partitions by GID |
Enter the number of partitions you want to split each group into. |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the component when an error occurs. This is an After variable and it returns a string. This variable functions only if the Die on error check box is cleared, if the component has this check box. A Flow variable functions during the execution of a component while an After variable functions after the execution of the component. To fill up a field or expression with a variable, press Ctrl+Space to access the variable list and choose the variable to use from it. For more information about variables, see Using contexts and variables. |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, appears only when you are creating a Spark Batch Job. Note that in this documentation, unless otherwise explicitly stated, a scenario presents only Standard Jobs, that is to say traditional Talend data integration Jobs. |
|
Spark Connection |
In the Spark
Configuration tab in the Run
view, define the connection to a given Spark cluster for the whole Job. In
addition, since the Job expects its dependent jar files for execution, you must
specify the directory in the file system to which these jar files are
transferred so that Spark can access these files:
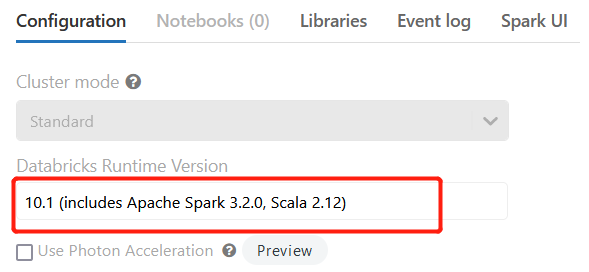
This connection is effective on a per-Job basis. When the Job is running on Spark 3.X with Databricks, go to the Databricks
cluster and select the Databricks runtime version 10.1 (includes
Apache Spark 3.2.0, Scala 2.12) or greater. Earlier versions are
not supported.
Check that the Scala version is 2.12.13 or greater. |