
Configuring the tMatchGroup component
Procedure
-
Click the Edit schema button to view the
input and output schema and do any modifications in the output schema, if
necessary.
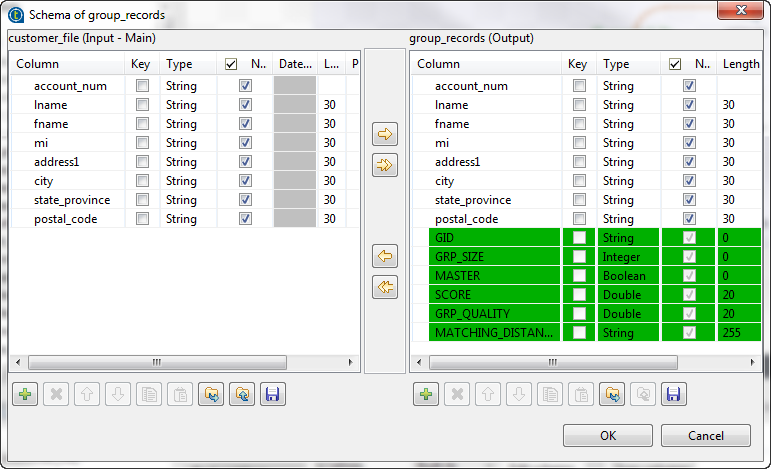 In the output schema of this component there are few output standard columns that are read-only. For more information, see tMatchGroup Standard properties.
In the output schema of this component there are few output standard columns that are read-only. For more information, see tMatchGroup Standard properties. -
Click the […] button next to
Configure match rules to open the configuration
wizard and define the component configuration and the match rule(s).
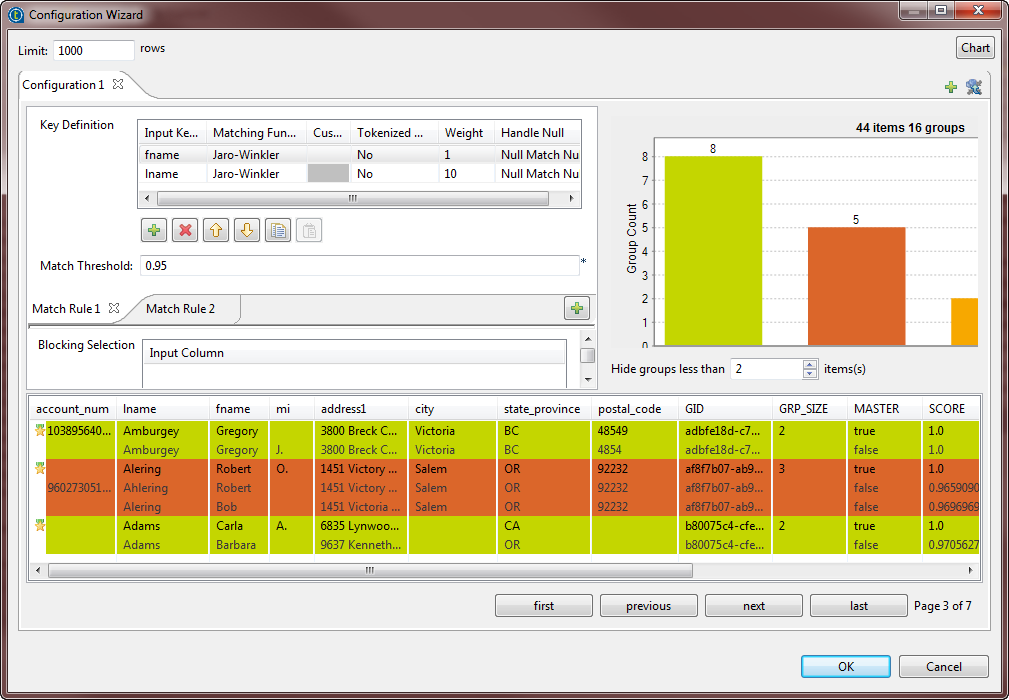 You can use the configuration wizard to import match rules created and tested in the studio and stored in the repository, and use them in your match Jobs. For further information, see Importing match rules from the studio repository.It is important to import or define the same type of the rule selected in the basic settings of the component, otherwise the Job runs with default values for the parameters which are not compatible between the two algorithms.
You can use the configuration wizard to import match rules created and tested in the studio and stored in the repository, and use them in your match Jobs. For further information, see Importing match rules from the studio repository.It is important to import or define the same type of the rule selected in the basic settings of the component, otherwise the Job runs with default values for the parameters which are not compatible between the two algorithms. -
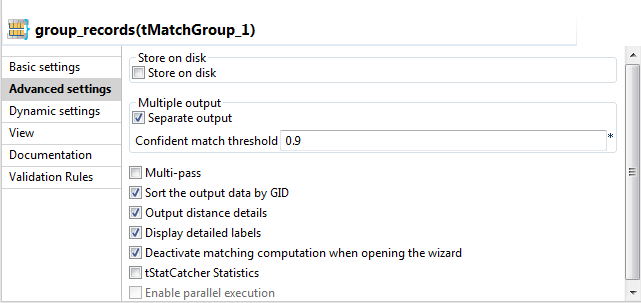
Click the Advanced settings tab and set the
advanced parameters for the tMatchGroup
component as the following:
-
Select the Separate output check box.
The component will have three separate output flows: Unique rows, Confident groups and Uncertain groups.
If this check box is not selected, the tMatchGroup component will have only one output flow where it groups all output data. For an example scenario, see Comparing columns and grouping in the output flow duplicate records that have the same functional key in Identification section.
-
Select the Sort the output data by GID check box to sort the output data by their group identifier.
-
Select the Output distance details and Display detailed labels check boxes.
The component will output the MATCHING_DISTANCES column. This column provides the distance between the input and the master columns giving also the names of the columns against which the records are matched.
-
Select the Deactivate matching computation when opening the wizard check box if you do not want to run the match rules the next time you open the wizard.
-
-
Click the Chart button in the wizard to
execute the Job in the defined configuration and have the matching results
directly in the wizard.
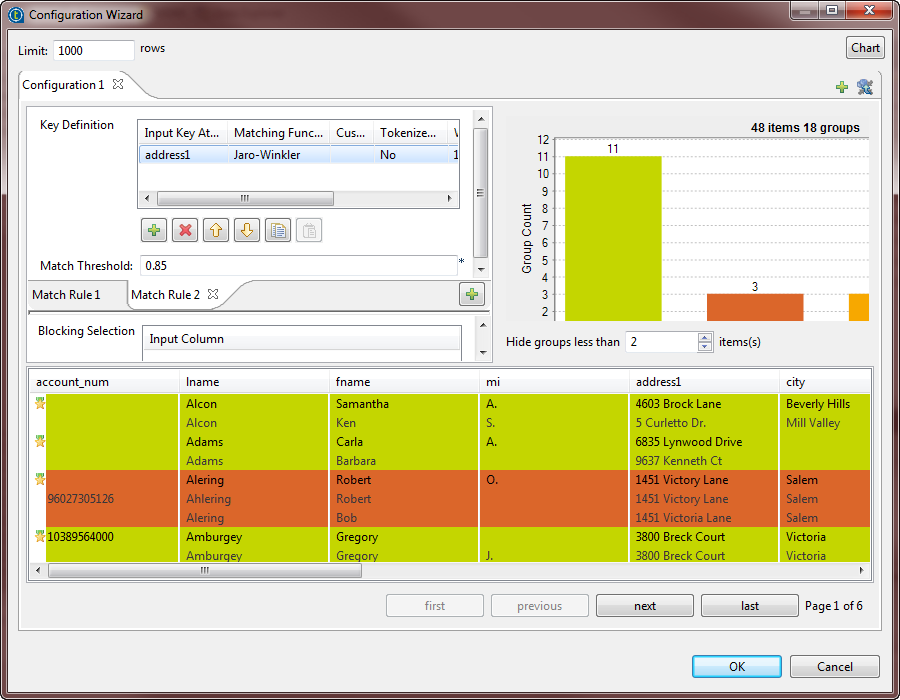 The matching chart gives a global picture about the duplicates in the analyzed data. The matching table indicates the details of items in each group and colors the groups in accordance with their color in the matching chart.The Job conducts an OR match operation on the records. It evaluates the records against the first rule and the records that match are not evaluated against the second rule. The MATCHING_DISTANCES column allows you to understand which rule has been used on what records. Some records are matched according to the second rule that uses address1 as a key attribute, whereas the other records in the group are matched according to the first rule which uses the lname and fname as key attributes.You can set the Hide groups of less than parameter in order to decide what groups to show in the matching chart and table
The matching chart gives a global picture about the duplicates in the analyzed data. The matching table indicates the details of items in each group and colors the groups in accordance with their color in the matching chart.The Job conducts an OR match operation on the records. It evaluates the records against the first rule and the records that match are not evaluated against the second rule. The MATCHING_DISTANCES column allows you to understand which rule has been used on what records. Some records are matched according to the second rule that uses address1 as a key attribute, whereas the other records in the group are matched according to the first rule which uses the lname and fname as key attributes.You can set the Hide groups of less than parameter in order to decide what groups to show in the matching chart and table