
Configuring the components
Procedure
-
Set the reference column as key column in the schema of the lookup flow.
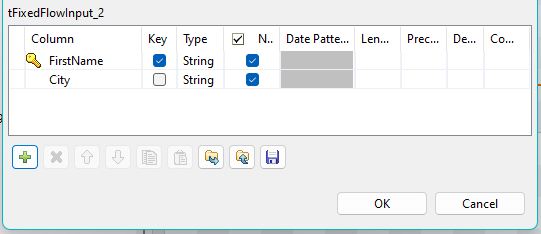
-
Double-click the tFuzzyMatch component to
open its Basic settings view, and check its
schema.
The Schema should match the Main input flow schema in order for the main flow to be checked against the reference.
 Note that two columns, Value and Matching, are added to the output schema. These are standard matching information and are read-only.
Note that two columns, Value and Matching, are added to the output schema. These are standard matching information and are read-only. -
Set the distance.
In this method, the distance is the number of char changes (insertion, deletion, or substitution) that needs to be carried out in order for the entry to fully match the reference.
 In this example, you set both the minimum distance and the maximum distance to 0. This means only the exact matches will be output.
In this example, you set both the minimum distance and the maximum distance to 0. This means only the exact matches will be output.